
Deploy the model to local device and imply real-time inference
Plan
-
Save the trained model and download it from Kaggle.
-
Prepare local environments
-
Object Oriented Programming
-
Inference
Code
import os import cv2 import numpy as np import pandas as pd import mediapipe as mp import tensorflow as tf from tensorflow.keras import layers from tensorflow.keras import optimizers from tensorflow.keras import Sequential CLASS_NAMES=['Left_Swipe_new','Right_Swipe_new','Stop_new','Thumbs_Down_new','Thumbs_Up_new'] output_directory ="temp_storage" class model: def __init__(self,CLASS_NAMES,model_pass,model2,output_directory): self.CLASS_NAMES=CLASS_NAMES self.model=tf.keras.models.load_model(model_pass) self.model.summary() self.model2=tf.keras.models.load_model(model2) self.output_directory=output_directory def detect_landmarks(self,image_folder): mp_holistic = mp.solutions.holistic.Holistic() image_files = sorted(os.listdir(image_folder)) num_frames = len(image_files) num_landmarks = 33 # Fixed number of landmarks for pose estimation landmarks = np.zeros((num_frames,num_landmarks, 2)) for i, file in enumerate(image_files): image_path = os.path.join(image_folder, file) frame = cv2.imread(image_path) # Convert the frame to RGB frame_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB) # Detect landmarks results = mp_holistic.process(frame_rgb) if results.pose_landmarks: for j, landmark in enumerate(results.pose_landmarks.landmark): landmarks[i, j,] = [landmark.x, landmark.y] mp_holistic.close() return landmarks def inference(self,X): #CLASS_NAMES=['Left_Swipe_new','Right_Swipe_new','Stop_new','Thumbs_Down_new','Thumbs_Up_new'] y_pred=np.argmax(self.model.predict(X), axis=1) #print(y_pred) print(self.CLASS_NAMES[y_pred[0]]) return y_pred def inference2(self,X): CLASS_NAMES=['not_move','move'] y_pred=np.argmax(self.model2.predict(X), axis=1) #print(y_pred) print(CLASS_NAMES[y_pred[0]]) return y_pred def clear_files(self,folder_path): # get all file in the folder files = os.listdir(folder_path) # delete them all for file in files: file_path = os.path.join(folder_path, file) if os.path.isfile(file_path): os.remove(file_path) print("-"*50) print("ALL Frames Cleared") def run(self): #self.clear_files(self.output_directory) frames = [] frame_count = 0 cap = cv2.VideoCapture(0) while True: ret, frame = cap.read() if ret: frame_name = os.path.join(self.output_directory, f"frame_{frame_count}.png") cv2.imwrite(frame_name, frame) frame_count += 1 if frame_count == 30: print("="*50) X_data = self.detect_landmarks(self.output_directory).reshape((1,30,66)) self.clear_files(self.output_directory) #y_check=self.inference2(X_data) frame_count = 0 #if y_check==1: y_pred=self.inference(X_data) print(f"Movement Type:{self.CLASS_NAMES[y_pred[0]]}, index:{y_pred[0]}") cv2.imshow('Camera', frame) if cv2.waitKey(1) & 0xFF == ord('q'): break cap.release() cv2.destroyAllWindows def main(): model(CLASS_NAMES,"231008RNNV5.h5","231012RNN_2V5.h5",output_directory).run() if __name__ == '__main__': main()
Evaluation
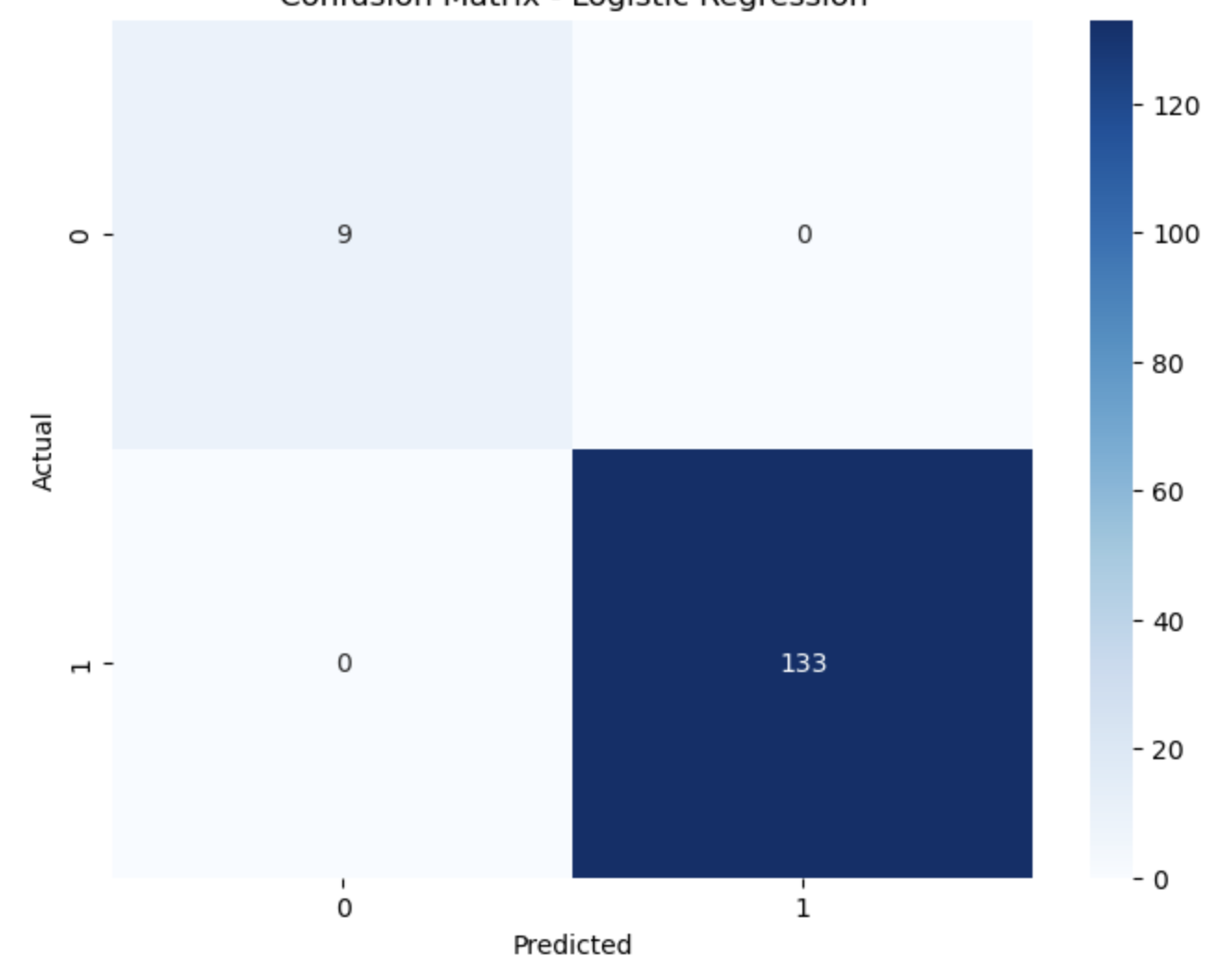
- The trained model can’t detect if a person is moving or not, meaning that if return non-sense result when the person infront of the camera is doing none of the movement. This problem can be solved by obtain a new model that detect rather someone is moving or not. I did train one of the model, the result was ok(shown in the confusion matrix below)
- Lack of computing power: Alhtough the inference work well, but it’s slow… Because the entire data collection, processinng, and inference were done in one while-loop, the time complexity of the model caused unacceptable delay. The camera are suppose to collect the video feed for each seconds, but the data processing and inference step caused to much delay, making it impossible to conduct real-time inference. Noticed that this issue CAN NOT BE SOLVED within the given amount of time
- Normally, GPU is required for any Deep learning task. GPU is suitable because it can execute multithreaded tasks while CPU can only excute singlethreaded tasks. I trained the model on Kaggle because it offers free GPU runtime. However, since the inference must be done locally to access local camera, making such task impossible to be done.
- This means I will NOT use the model to control the drone as the delay will lead to possible hazard and might cause property damage and personnel casualties. The model is not capable to actually deploy on the drone as well as my current device.
Possible Future Approach
I will still use the video feed from the drone’s camera as input with the help of the library djitellopy, but I will not use the result of the inference to control the drone due to safty and technical consideration.