New Appraoch with RNN
Version
 All versions were saved on Kaggle
All versions were saved on Kaggle
Data
It seems like using CNN model is not a successful approach based on my physical test. The model highly depand on shooting angle and position condition. This will definitally not work with any real life situation. Thus, we consider body landmarks this time and try a new approach with RNN model
Model
Recurrent Neural Networks (RNNs) are a type of artificial neural network designed to recognize patterns in sequences of data, such as text, genomes, handwriting, or spoken words. Unlike traditional neural networks, RNNs have loops, allowing information to persist, which makes them ideal for tasks involving sequential data.
In an RNN, the output from a previous step is given as input to the current step, creating a ‘memory’ of information processed so far. However, RNNs can struggle with long-term dependencies due to the “vanishing gradient” problem, where the influence of information decays over time.
Variants like Long Short-Term Memory (LSTM) and Gated Recurrent Units (GRU) networks have been developed to address this issue, allowing the network to learn longer sequences and retain information for longer periods. Here we use GRU layer.
Code
import os
import cv2
import numpy as np
import pandas as pd
import mediapipe as mp
Data Pre-proccessing
Since the CNN model using all pixels has the problem of overfitting and lack of generalization ability, using body landmarks might be better
import os
import numpy as np
import cv2
import mediapipe as mp
#This function detect the body landmarks from all the images in a folder and output an array with size(30,33,2) that contains the landmakrs
def detect_landmarks(image_folder):
mp_holistic = mp.solutions.holistic.Holistic()
image_files = sorted(os.listdir(image_folder))
num_frames = len(image_files)
num_landmarks = 33 # Fixed number of landmarks for pose estimation
landmarks = np.zeros((num_frames,num_landmarks, 2))
for i, file in enumerate(image_files):
image_path = os.path.join(image_folder, file)
frame = cv2.imread(image_path)
# Convert the frame to RGB
frame_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
# Detect landmarks
results = mp_holistic.process(frame_rgb)
if results.pose_landmarks:
for j, landmark in enumerate(results.pose_landmarks.landmark):
landmarks[i, j,] = [landmark.x, landmark.y]
mp_holistic.close()
return landmarks
initialize empty array for the data and process data
train_size = train_csv.shape
i = 0
label = []
Name = []
train_landmarks = np.empty((662,30,66))
for n in range(train_size[0]):
subPath = train_csv.loc[n,'File'] #get name of the sub file from train_csv
folder_path = '/kaggle/input/gesture-recognition/train/'+subPath #path of the subfile
print(folder_path )
print(n)
train_landmarks[n] = detect_landmarks(folder_path).reshape((30, 66))
label.append(train_csv.loc[n,'Inde'])
Name.append(train_csv.loc[n,'Name'])
np.save('/kaggle/working/train_landmarks.npy', train_landmarks)
np.save('/kaggle/working/label.npy',label)
np.save('/kaggle/working/name.npy',Name)
print(50*"=")
print('saved')
Model Training
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Print the shapes of the resulting datasets
print("X_train shape:", X_train.shape)
print("y_train shape:", y_train.shape)
print("X_test shape:", X_test.shape)
print("y_test shape:", y_test.shape)
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras import optimizers
from tensorflow.keras import Sequential
# Build Model
model = Sequential([
layers.Input(shape=(30,66)),
layers.GRU(100, return_sequences=False),
layers.Dense(len(CLASS_NAMES), activation="softmax")
])
model.compile(
optimizer=optimizers.Adam(0.001),
loss="sparse_categorical_crossentropy",
metrics=["accuracy"]
)
model.summary()
filepath = "/kaggle/working/"
checkpoint = tf.keras.callbacks.ModelCheckpoint(
filepath, monitor='val_accuracy', save_weights_only=True, save_best_only=True, verbose=1
)
history = model.fit(
X_train,
y_train,
validation_data=(X_test, y_test),
epochs=60,
callbacks=[checkpoint],
)
Evaluate
On Validation Data
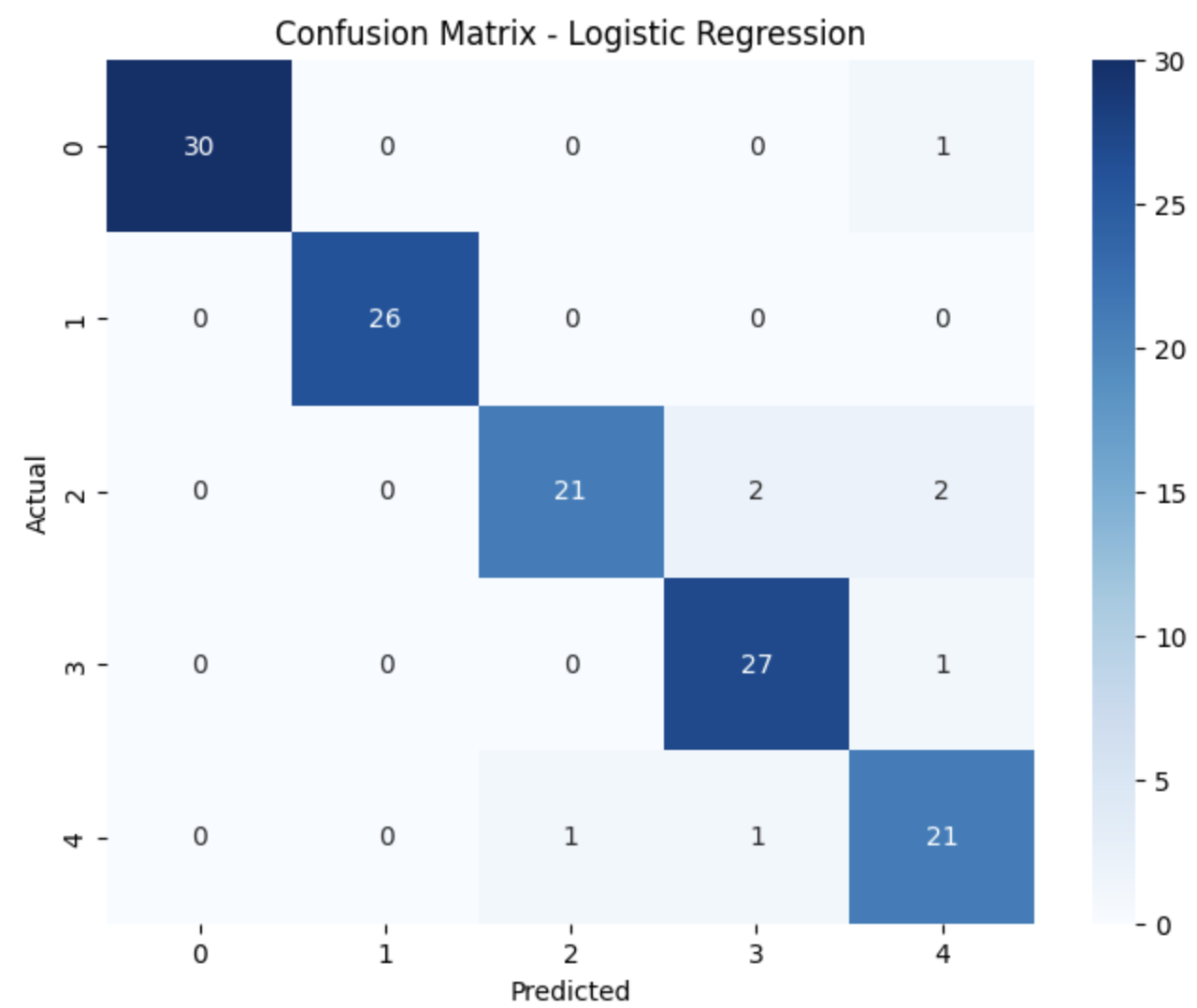 Again, the model works well on validation data set. The confusion matrix suggested that almost all the prediction made by the model is correct. Small error occurs with #3 and #4, but it dosen’t affect the model’s overall accuracy.
Again, the model works well on validation data set. The confusion matrix suggested that almost all the prediction made by the model is correct. Small error occurs with #3 and #4, but it dosen’t affect the model’s overall accuracy.
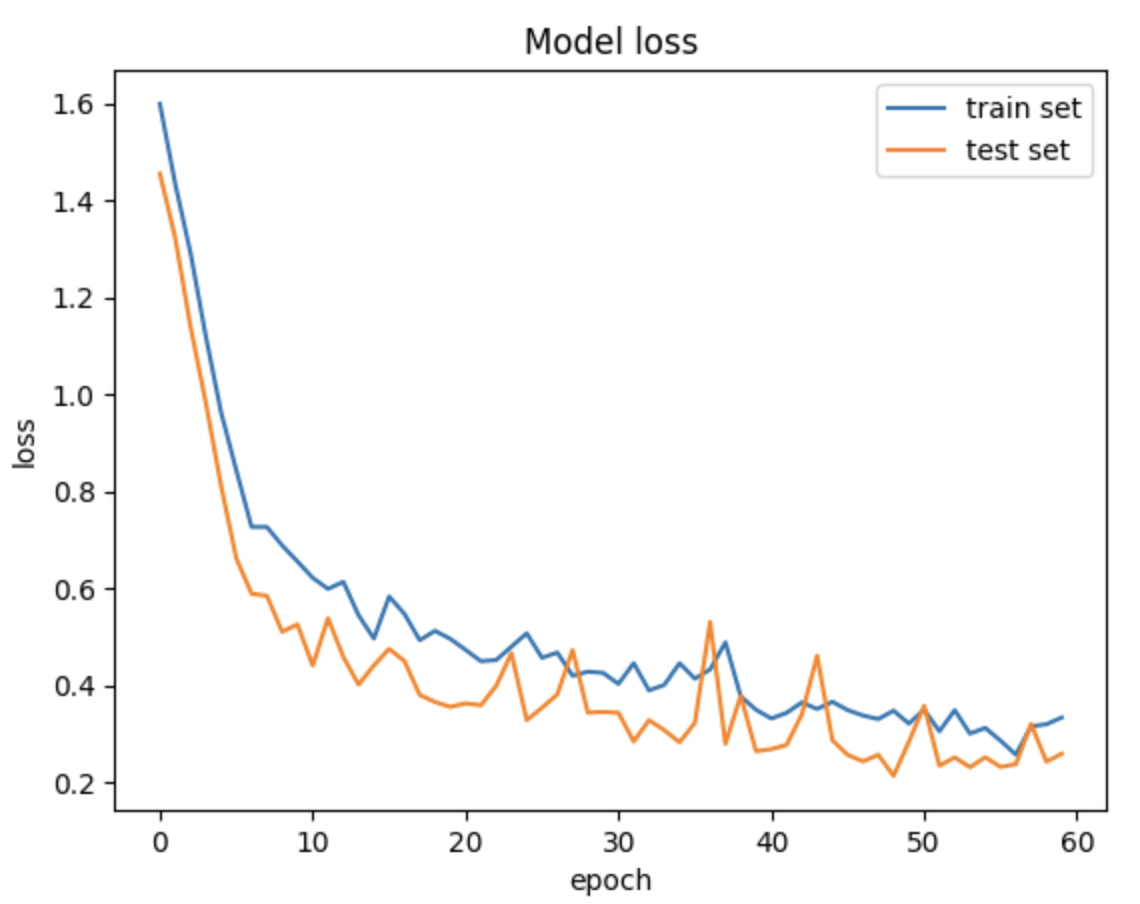
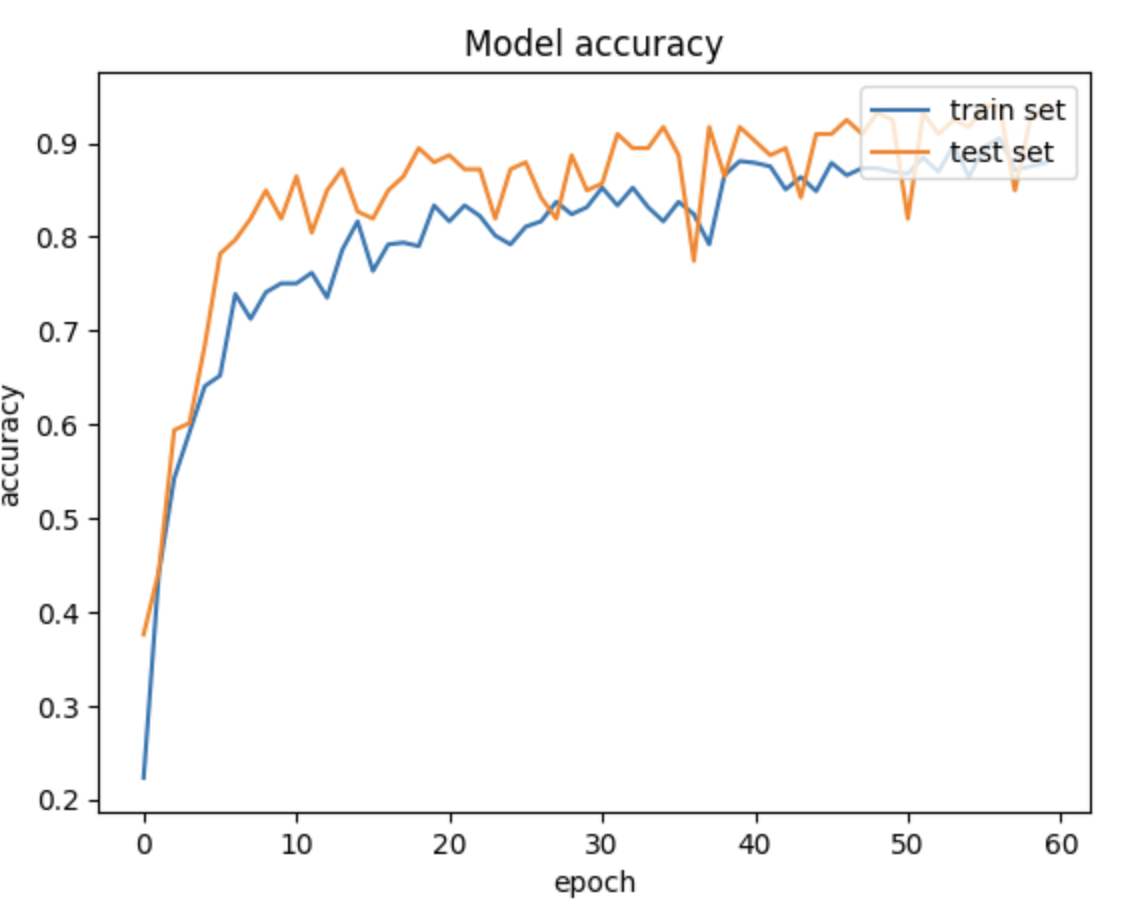
Furthermore, the loss of the model on validation data is generally lower than the value on training data, meaning that there is no over fitting. The accuracy data also suggest the same conclusion.